
【ODCC专家视角】Key Value:数据库的杀手技术
近年来,互联网行业发展的越来越快,在人手一台智能终端的今天,每时每刻都有着无数的人在访问互联网企业的数据库。这就要求数据库不但能够支持海量数据的存储,而且还要具有高并发,易扩展等特性。然而传统的数据库往往很难满足这些需求,加上很多时候系统需要是基于主键的检索,传统数据库在这种情况下的效率较低,使得越来越多的企业开始拥抱Key-Value数据库。
在Key-Value数据库中,key可以是文件名、地址、hash值或其他字符串,value可以是任意类型的数据,如图像、音频、视频或文档等等。但这些数据大多都是以文件的形式存储在硬盘上的,Key-Value数据库在获取数据时需要先调用数据库的KV接口,找到该KV键值对存储在哪个文件中,然后再找到该文件对应的LBA,最终将数据请求通过driver发送到物理硬盘上并找到真正的PBA来获取数据。

整个过程需要完成从key到file, file到LBA, 再从LBA到PBA的数据转换。
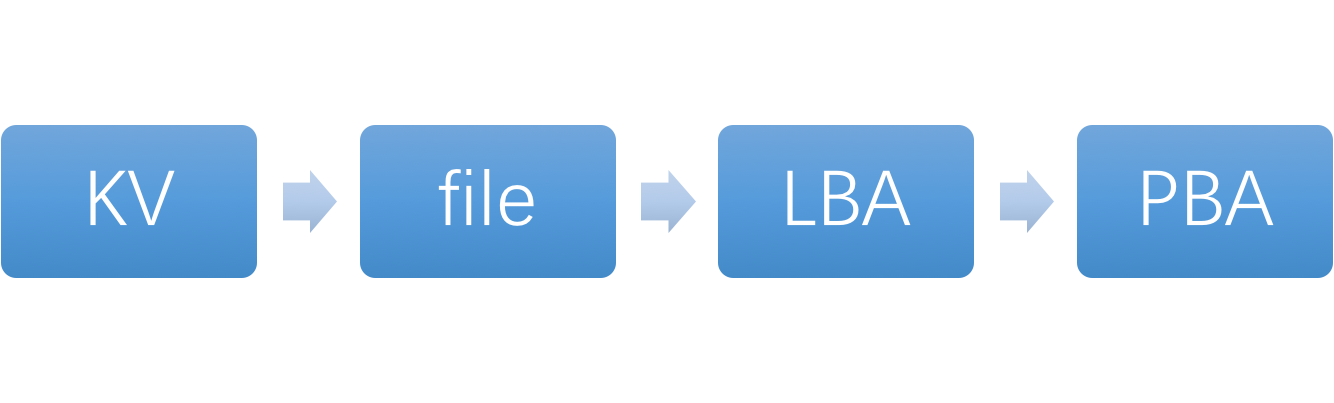
这种数据存取模式在机械硬盘上并没有表现出太多的劣势,但是随着固态硬盘应用地越来越广泛,存储速度越来越快,这种数据转换所消耗的资源也越来越多,在某些情况下就会变成整个系统的性能瓶颈。
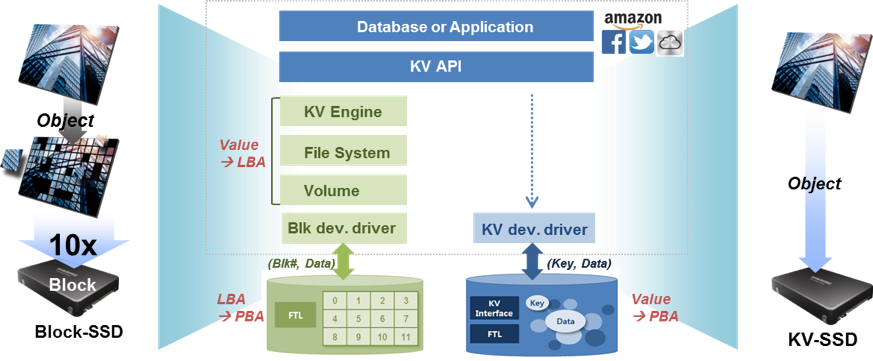
为了解决这个问题,近来业界提出了一种新的解决方案:Key-Value SSD。这种SSD采用了一种增强的FTL(Flash Translation Layer),实现了KV存储的部分核心功能,向外提供KV接口,能够直接响应host端应用程序的KV请求。将KV SSD与KV数据库或KV存储引擎(如RocksDB)配合使用,在诸多方面都会带来较大的提升。
KV数据库从KV SSD中读写数据时可以调用KV SSD提供的KV接口,将KV的读写请求直接转换为对PBA的请求,省去了从key到file,再从file到LBA的转换,简化了数据读写的流程,不但提高了数据读写的效率,还大大减少了主机端CPU和内存的消耗。
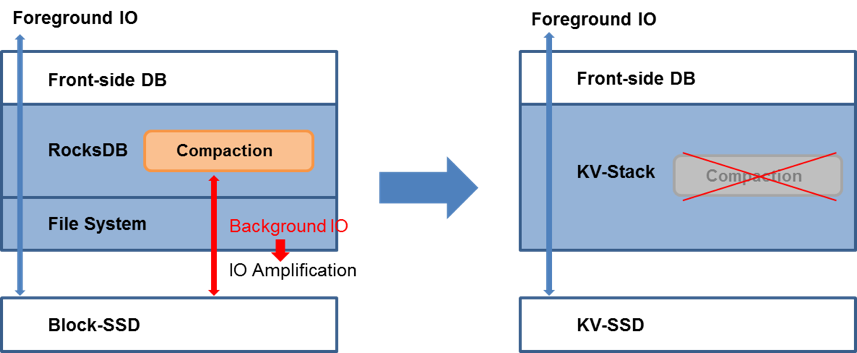
像RocksDB这样的KV存储引擎采用的是LSM Tree的方式来分层存储数据,对记录的更改不是在系统中找到旧的数据进行修改,而是直接将新的记录以Append的方式写入到内存中,然后再flush到数据库的第一层。每层的数据写到一定容量之后就会触发compaction操作,将该层的一些文件里的key-value重新排序,去除旧的数据记录,融合成新的文件写入到下一层。这种机制产生了很多Background IO,消耗了一定的SSD带宽,不但影响了系统的性能,还使得RocksDB在运行时有着高达10倍的写放大。而KV SSD提供了原生的KV接口,RocksDB可以将新的数据记录直接写入到SSD中,不需要再进行反复的compaction操作,从而将RocksDB的写放大减小到了1,而NAND本身就不支持覆盖写入的特性使得SSD端的写放大并没有显著增加,所以整体来看,KV SSD降低整个系统写入放大的效果还是很明显的。
到现在为止,系统性能扩展采用的方式都是增加服务器的数量或者使用性能更强的处理器,这种方式不但会使增加整个系统的成本,同时也会增加对功耗和数据中心场地的需求。而KV SSD具有一定的数据处理能力,同时又能降低对Host端CPU以及内存的消耗,所以使用KV SSD可以更高效的扩展系统的性能。
虽然KV SSD在诸多方面都有着传统SSD无法比拟的优势,但是想方便地,广泛地在数据库系统中部署KV SSD还不是一件很容易的事。从前面的流程图中可以看到,KV SSD是一个系统的解决方案,需要SSD驱动以及客户应用程序的相互配合才可以实现。同时由于客户的应用程序千差万别,对接口的需求也各不相同,所以急需SSD厂商和客户相互配合,共同制定出一个KV SSD的接口及应用标准,以方便广大客户方便地在系统中部署KV SSD。
ODCC 致力于数据中心领域新技术的标准制定和技术推广,在今年4月的ODCC存储峰会上将就相关的存储新技术带来更多的分享与交流。

作者:豆坤
三星(中国)半导体有限公司西安研究所高级工程师
主要从事NoSQL数据库,企业级SSD的测试与验证,以及SSD先进应用技术的研究。
曾在NVMW2015发表题为“Multi-streaming RocksDB”的论文,并在IEEE CBDCom2015上做了题为“Optimizing NoSQL DB on Flash - A Case Study of RocksDB”的技术分享。
